When the dates were finally announced for IndiaFOSS 2025, I didn’t think twice—I grabbed an early bird ticket and circled the weekend in my calendar. Over the next few months, the anticipation kept building. By the time September rolled around, I was more than ready.
And just like that, on the 20th and 21st of September 2025, I found myself walking into the NIMHANS Convention Center in Bangalore, joining hundreds of other FOSS enthusiasts. This blog is my attempt to capture the highlights of that weekend—the talks that fascinated me, the ideas that got me thinking, and the moments that reminded me why I love open source so much.
Day 1
CDN for Open Source Software – Albony
 The first talk I attended set the tone right away. It was about the architecture, technical details, and challenges of running a CDN at scale, presented by Shrirang Kahale and Albert Sebastian, the maintainers of Albony.
The first talk I attended set the tone right away. It was about the architecture, technical details, and challenges of running a CDN at scale, presented by Shrirang Kahale and Albert Sebastian, the maintainers of Albony.
Albony is a student-run CDN service that mirrors open-source projects like Ubuntu and Kali Linux. Now, when I think “CDN,” I picture rows of servers with blinking lights in a fancy data center. But Albony’s story was refreshingly different. Sure, they have a proper server rack in one location, but a lot of their nodes are… well, much simpler. Shrirang’s node in Nagpur? Just an office PC strapped to a UPS.
And yet, this scrappy setup reliably pushes 600 TB of traffic every month. I loved how they walked us through their approach to load balancing and fault tolerance at scale. It felt very much in the spirit of open source—resourceful, community-driven, and practical.
Ente Photos – Private ML in Action
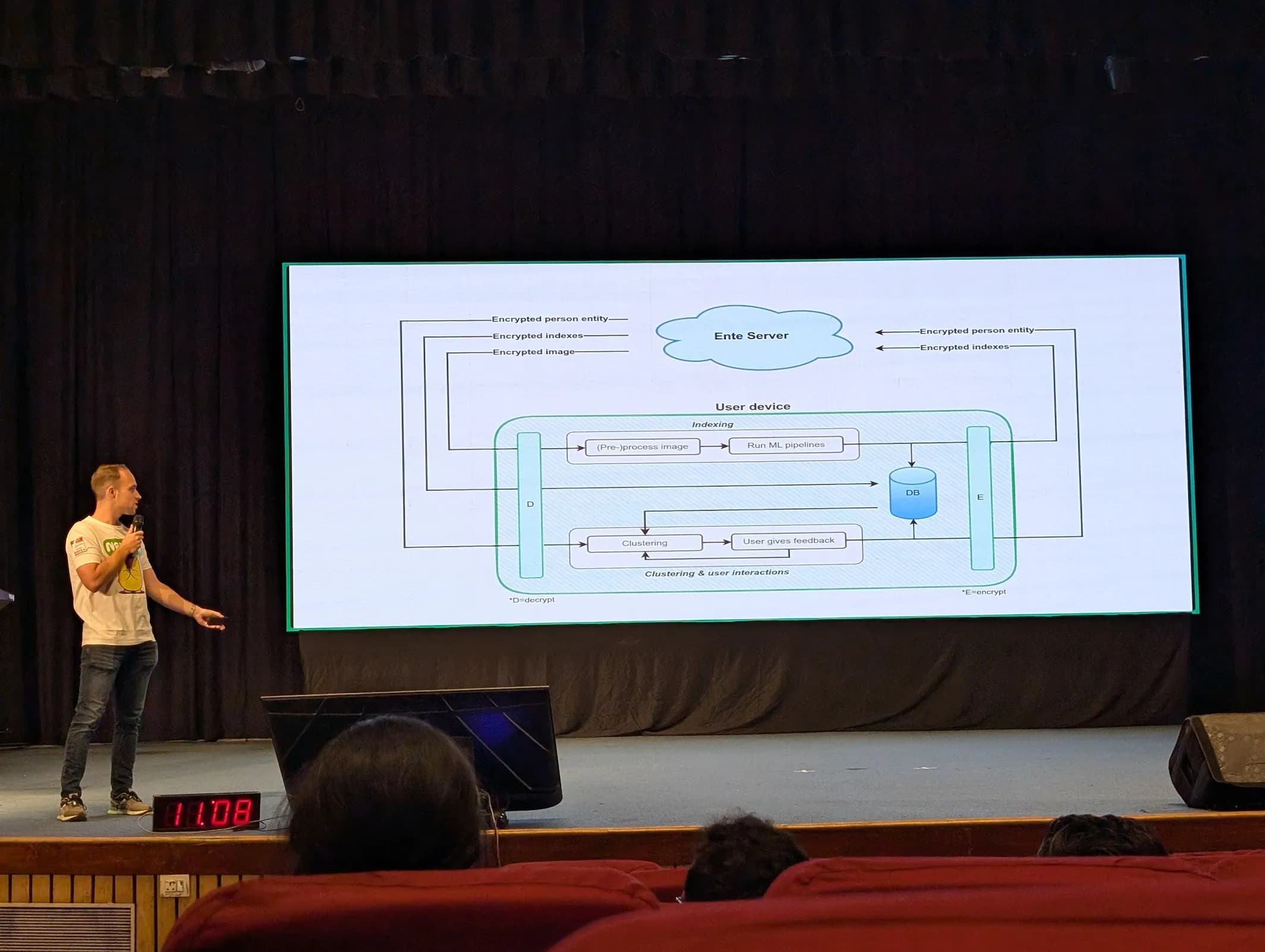 Next up was Ente Photos. If you’ve ever used Google Photos, you’ll get the idea—face recognition, semantic search, object detection, and so on. But Ente adds one huge twist: privacy.
Next up was Ente Photos. If you’ve ever used Google Photos, you’ll get the idea—face recognition, semantic search, object detection, and so on. But Ente adds one huge twist: privacy.
All the AI processing happens on the client side, and everything stored on the server is end-to-end encrypted. The tradeoff? They can’t constantly train on user data like Google does. The upside? Your photos remain yours—no prying eyes.
Under the hood, Ente uses open-source models like YOLOv8 (for object recognition) and a derivative of OpenAI’s CLIP (for semantic search). They also spoke about homomorphic cryptosystems—encryption systems that would, in theory, let companies train models without ever decrypting user data. It’s still a long way from being practical, but hearing them talk about it reminded me of my own B.Tech project, where I had explored this exact topic. It was a nice full-circle moment.
LibreFin – An Open Source UPI App
When I saw “open-source UPI app” on the schedule, my first thought was: How hard could that be? But as the session unfolded, I quickly realized it was anything but simple.
UPI isn’t designed to be hackable. The protocol isn’t documented publicly, and the APIs are closed. Building LibreFin meant reverse-engineering how existing UPI apps work, figuring out the NPCI common library, and then making that knowledge available to the open-source community.
What started as something I assumed would be straightforward turned out to be a deep dive into reverse engineering, protocol analysis, and a real testament to persistence.
Day 2
On Day 1, I had missed the compilers devroom because it was already full when I arrived. Lesson learned: I got to the venue early on Day 2. (The excellent breakfast didn’t hurt either!)
The day’s lineup was just as exciting. There was a beginner-friendly session on kernel development that busted the myth that only “Linux wizards” can touch kernel code, and a talk on end-to-end video encryption. But here are the ones that left the strongest impression on me.
Bootable Containers
Imagine booting your entire operating system from a Docker container. That’s what bootc is aiming for.
Instead of going the declarative route like NixOS, bootc wants to give everyday users many of the same advantages—predictability, reproducibility, and reliability—without the steep learning curve. The goal? To make foolproof Linux distros that “just work.”
It’s an ambitious idea, and I’m curious to see how it evolves.
HUML – Is YAML Really That Readable?
 This talk by Kailash Nadh, CTO of Zerodha, was equal parts funny and thought-provoking.
This talk by Kailash Nadh, CTO of Zerodha, was equal parts funny and thought-provoking.
We all know YAML is supposed to be human-readable, but anyone who’s worked with it for long knows it can be a pain. Flexible, yes. Predictable? Not so much.
There is nobody who has used YAML for a reasonable amount of time who hasn’t been bitten by it.
Kailash backed this up with examples, including the fact that there are 63 ways to write a list in YAML. His answer to this chaos is HUML (Human Oriented Markup Language). Unlike YAML, HUML enforces one way of doing things. That means less flexibility, but also fewer surprises.
In HUML, many things you casually write in YAML would trigger a Parser Error. It’s opinionated by design, and that’s the point—more predictability, less guesswork. It was one of those talks that made me rethink tools I use every day.
Diff Graphs – Do Diffs Scale?
The final talk that stood out to me tackled a simple but important question: do diffs scale?
The Argument
In an age where hundreds of lines of code can be generated in seconds—often by AI—traditional line-by-line diffs are starting to feel inadequate. Human mistakes tend to look one way, while AI mistakes (hallucinations, context window issues, broken relationships between variables) look very different. Yet we’re still reviewing code the same old way.
The Solution
The proposed tool, diffgraph, is a wrapper around Git that swaps git diff for an LLM-powered graph view. Instead of showing raw lines of code, it generates an HTML graph of relationships between functions, variables, and modules.

My Take
It’s clever, no doubt. The bird’s-eye view can make large changes easier to digest. But I’m not entirely convinced it can replace git diff.
- The graphs are generated with LLM help, which makes me question reliability.
- They’re harder to navigate than traditional diffs.
- And they risk missing small but important details.
Still, as a supplement, I think it’s brilliant. It’s the kind of tool I’d want in my toolbox, even if I wouldn’t throw away git diff just yet.
Closing Thoughts
By the end of Day 2, I was both exhausted and energized. IndiaFOSS 2025 turned out to be exactly what I had hoped for: a weekend packed with inspiring talks, deep technical insights, and conversations that made me think differently.
But more than that, it was about the people—the hallway chats, the connections, the sense of being part of a community that genuinely cares about open source.
As I left the venue, one thought came to mind: I’m definitely coming back next year.